⚠️ I am not a machine learning expert. This article is a summary of what I have learned about model merging from my own experience. If you notice any mistakes, please kindly point them out, and I will correct them as soon as possible.
In this article, I will introduce what model merging is and walk you through the complete process of merging multiple models to combine their strengths with mergekit, and then quantize the GGUF files with the help of imatrix for use in llama.cpp, Ollama, and LM Studio. I hope this article provides a helpful starting point for beginners looking to explore model merging.
0. What is Model Merging
In short, model merging is a technique that combines multiple models with different strengths and abilities, allowing the resulting model to inherit the advantages of each. For example, merging an abliterated (uncensored) model with a storytelling fine-tuned model can create a model that both refuses less and excels at storytelling.
Although merged models usually perform worse than fine-tuned models or multi-task learning models, it is significantly easier and cheaper to perform. With the right blend and parameters, it can still yield excellent results. Moreover, as merging techniques advance over time, the performance of merged models is expected to improve.
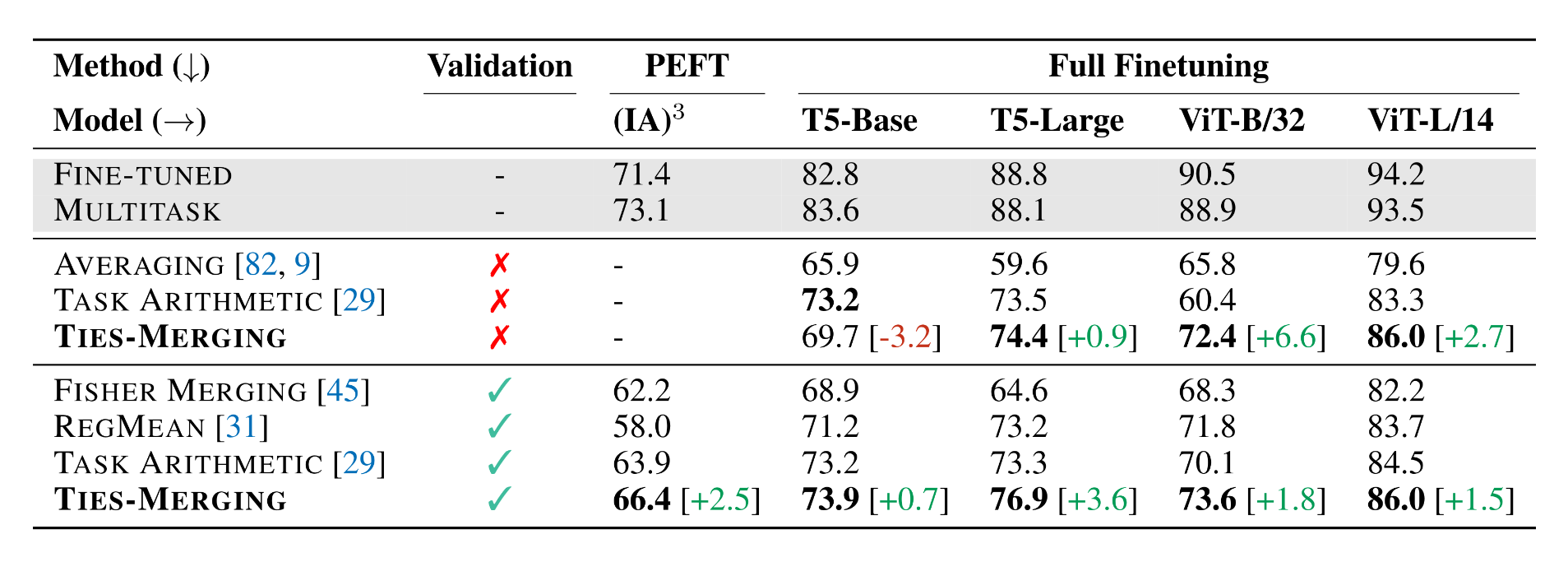 Figure 1: Comparing model merging methods across multiple fine-tuning settings and modalities (NLP and Vision) with and without the availability of a validation set (source).
Figure 1: Comparing model merging methods across multiple fine-tuning settings and modalities (NLP and Vision) with and without the availability of a validation set (source).
Model merging works based on the finding that different “task vectors (delta parameters)” representing different capabilities of the models are typically close to orthogonal.
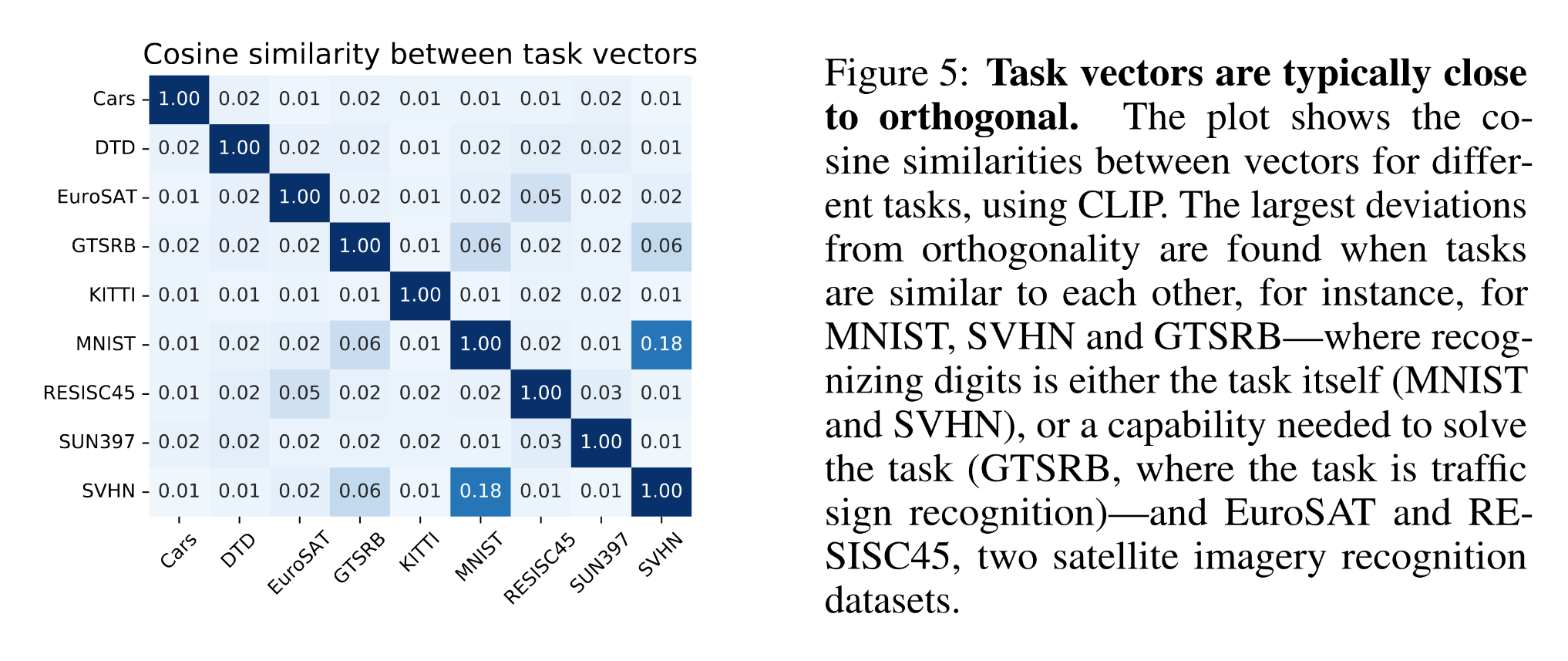 Figure 2: Cosine similarity between task vectors (source)
Figure 2: Cosine similarity between task vectors (source)
I recommend reading the articles below to learn more about the technical aspects of model merging. The rest of this article will focus more on the hands-on process of merging models rather than the theoretical aspects.
- Editing Models with Task Arithmetic
- TIES-Merging: Resolving Interference When Merging Models
- Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
- 模型融合(Model Merging):合理性、常见技术及其特性
1. Set Up the Environment
I will be using an Arch Linux Docker container as the merging environment for this demonstration. I chose Arch Linux because I find it the easiest to compile programs like llama.cpp with CUDA support on this distro. You can choose any distro you prefer and adjust the commands according to your environment. I will be using mergekit to perform model merging and use Hugging Face as the model repository as they are the most popular options for this task.
Install the build dependencies for mergekit and huggingface-cli:
|
|
Create a Python virtual environment and install mergekit and gguf-py. mergekit is the tool that we will use to merge models; gguf-py is required by llama.cpp scripts to convert the Safetensors model files to GGUF for llama.cpp, Ollama, and LM Studio.
|
|
Optionally, you may enable Hugging Face CLI to use hf_transfer to speedup data transfer:
|
|
You can also write this setting to /etc/environment to make it permanent:
|
|
You will also need to install llama.cpp. You can either download and extract their latest pre-compiled binaries or compile it yourself. Since I’m using Arch Linux and an NVIDIA GPU, I will be installing the llama.cpp-cuda-f16 package from the Arch User Repository (AUR) with yay:
|
|
When compiling llama.cpp-cuda-f16 in an Arch Linux container, you might run into issues with CMake not being able to find the CUDA toolkit. You can provide the paths manually by setting the CUDAToolkit_ROOT and CUDACXX environment variables. yay will also install the cuda package, which might conflict with the driver files mounted when --gpus all is specified in Docker. You can use --overwrite='*' to force the overwrite of these conflicting files.
|
|
2. Merge Models with mergekit
We need to write a mergekit configuration file that specifies which models we want to merge with what method, and the detailed merging parameters.
The goal for this demo is to produce a model that is good at storytelling and role-playing, has less positive bias, and refuses less user requests. I chose the following models to merge based on these requirements:
- nbeerbower/Llama-3.1-Nemotron-lorablated-70B: NVIDIA’s customized nvidia/Llama-3.1-Nemotron-70B-Instruct-HF model further LoRA fine-tuned to reduce refusal. This model is used as the base model and provides the basic capabilities.
- SicariusSicariiStuff/Negative_LLAMA_70B: Llama 3.3 fine-tuned to reduces the model’s positive bias.
- LatitudeGames/Wayfarer-Large-70B-Llama-3.3: Llama 3.3 fine-tuned for role-playing to allow darker, conflicting, and challenging outputs.
- Sao10K/L3.3-70B-Euryale-v2.3: Llama 3.3 fine-tuned for storytelling and creativity.
- TheDrummer/Anubis-70B-v1: Llama 3.3 fine-tuned for storytelling and creativity.
For this demo, we will not be adjusting any advanced parameters like lambda, weight, or density. Different merge methods have different strengths and support different parameters. You can refer to mergekit’s documentation and this article for more information. I chose the SCE merging method, mostly because it is relatively new. You may also experiment with different merge methods. The output data type is set to bfloat16, the common choice for AI models. Finally, we write the configuration file for mergekit:
|
|
You can now start merging the models with the command below. I will name the model Demo-LLaMA-70B. You can also use flags like --gpu-rich or --cuda to accelerate merging if you have enough VRAM.
|
|
The merged model will be stored in the Safetensors format. You can use a compatible runtime like vLLM to test the merged model to see if it is satisfactory.
3. Convert the Model to GGUF
After the merging finishes, we can convert the model stored in the Safetensors format to the GGUF format so it can be run on llama.cpp, Ollama, and LM Studio by end users. llama.cpp has a Python script that can help with this conversion.
Clone llama.cpp’s repository:
|
|
Run llama.cpp’s Python script to convert the model from Safetensors into GGUF:
|
|
After the conversion, you may want to test the model to make sure that it works (e.g., no NaN values in weights):
|
|
4. Compute the Importance Matrix (imatrix)
The importance matrix (imatrix) is a technique we can use to improve the quality of the quantized model without increasing its size. The imatrix identifies which weights are “salient,” meaning that they have greater influence on the output. By allocating more precision for these salient weights, we can achieve better quantization results.
We will need to compute and calibrate an imatrix with some data to help it identify the salient weights. For this demo, I’m using bartowski’s calibration datav3 as the imatrix calibration data. We download and save it to a file:
|
|
We can then calibrate the imatrix with llama.cpp’s llama-imatrix tool. You can set the -ngl N option to offload N layers of the model to the GPU to help accelerate the calibration.
|
|
Having fast GPUs with lots of VRAM that allow you to fully offload the calibration to the GPUs will help a lot in this step. As an example, without GPU offloading, this step takes more than five hours to complete on the CPU; with GPU offloading to four A40 GPUs, it takes only 15 minutes.
5. Quantize Model
There are many quantization types you can choose from. You can refer to this guide to determine which quantization type to use. At the time of writing this article, I recommend choosing the largest quantization type that you can fit in your VRAM among IQ4_XS, Q4_K_M, Q5_K_M, Q6_K, and BF16 (i.e., no quantization, if it fits). You can see all the available quantization types with llama-quantize -h. Remove the --imatrix argument from the command if you chose not to use an imatrix.
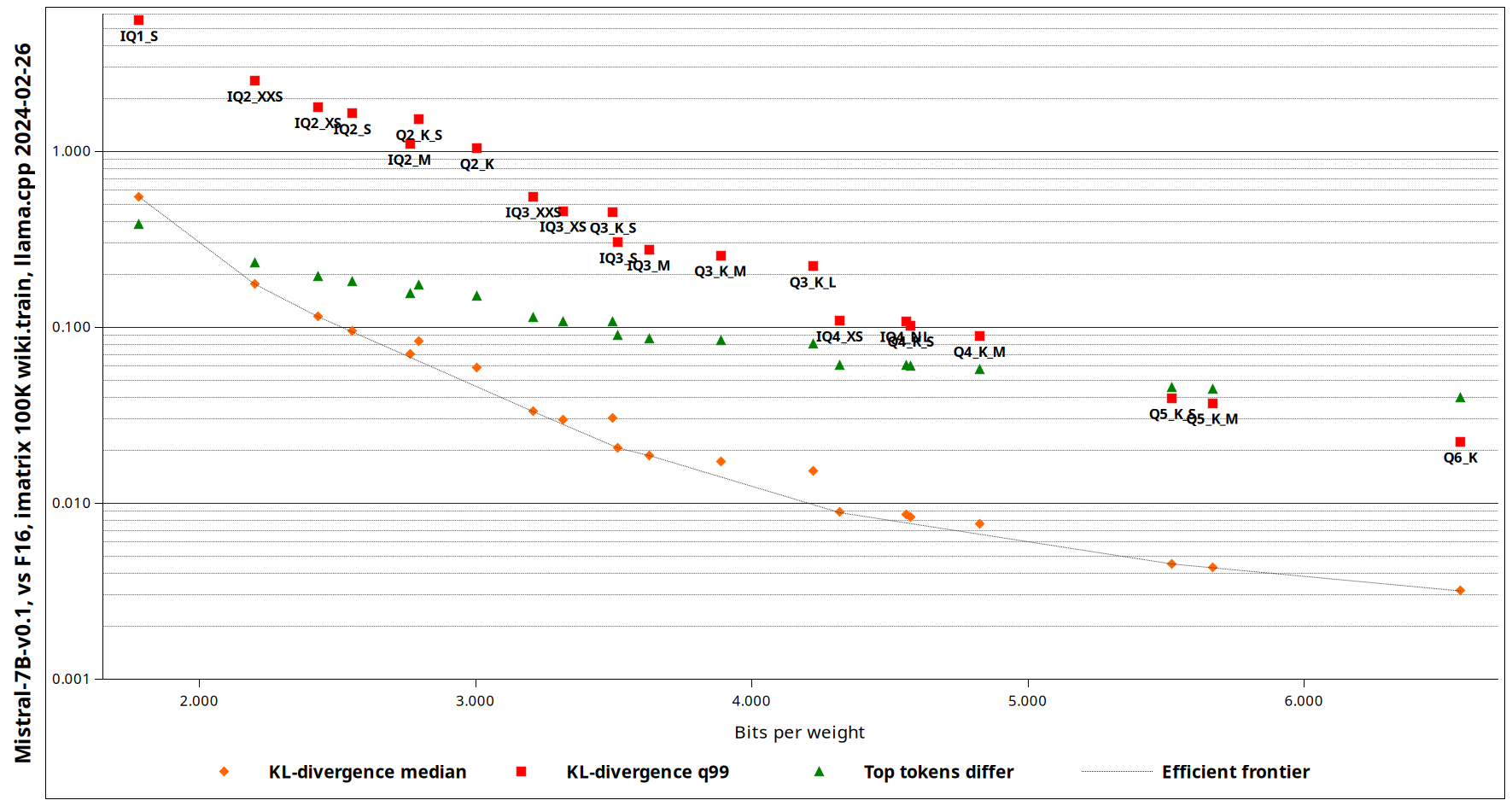 Figure 3: A comparison of KV-divergence between different quantization types supported by llama.cpp (source)
Figure 3: A comparison of KV-divergence between different quantization types supported by llama.cpp (source)
Once you determine which quantization type to use, run the command below to quantize the model.
|
|
Since platforms like Hugging Face limit the maximum size of individual files, we can use llama-gguf-split to split large GGUF files into multiple smaller files. Hugging Face has a size limit of 50 GiB for a single file, so we can split the bfloat16 model that is likely larger than 50 GiB into multiple smaller files with each file’s size not exceeding 50 GiB.
|
|
6. Upload Model Files
Finally, you can upload the file to Hugging Face for storage and sharing.
You can use the commands below to upload the Safetensors model files to a Hugging Face repository. Sharing the Safetensors files allows other users to easily merge your model with other models or fine-tune your model.
|
|
You can use the commands below to upload the GGUF model files to a Hugging Face repository. Sharing the GGUF files allow end users to easily run your model in common inferencing frameworks like llama.cpp, Ollama, and LM Studio.
|
|
For more information on how to use the huggingface-cli tool, visit its documentation page.
7. Afterword
Model merging is a cost-effective yet powerful technique that can enhance a model’s performance by combining the strengths of multiple models. It provides an efficient way to improve results without the need for expensive continued pre-training or fine-tuning. I had a great time experimenting with different merges of models and playing them in Telegram groups using Tellama. I hope you found this article both informative and useful, and that it inspires you to have your own fun with merging models.